Task description
The participating systems will be asked to generate new translations automatically among three languages, English, French, Portuguese, based on known translations contained in the Apertium RDF graph. As these languages (EN, FR, PT) are not directly connected in the graph, no translations can be obtained directly among them there. Based on the available RDF data, the participants will apply their methodologies to derive translations, mediated by any other language in the graph, between the pairs EN/FR, FR/PT and PT/EN.
Participants may also make use of other freely available sources of background knowledge (e.g. lexical linked open data and parallel corpora) to improve performance, as long as no direct translation among the target language pairs is applied.
Beyond performance, participants are encouraged to consider the following issues in particular:
- The role of the language family with respect to the newly generated pairs
- The asymmetry of pairs, and how translation direction affects the results
- The behavior of different parts of speech among different languages
- The role the number of pivots plays in the process
About the input data source
Apertium is a free open-source machine translation platform. The system was initially created by the Universitat d’Alacant and it is released under the terms of the GNU General Public License. In its core, Apertium relies on a set of bilingual dictionaries, developed by a community of contributors, which covers more than 40 languages pairs. Apertium RDF is the result of publishing 22 Apertium bilingual dictionaries as linked data on the Web. The result groups the data of the (originally disparate) Apertium bilingual dictionaries in the same graph, interconnected through the common lexical entries of the monolingual lexicons that they share.

The picture above illustrates such unified graph. The nodes in the figure are the languages and the edges are the translation sets between them. The darker the colour, the more connections a node has. All the generated information is accessible on the Web both for humans (via a Web interface) and software agents (with SPARQL). All the datasets are documented in Datahub. A simple, multilingual Search Interface is also available.
[Further reading: for an informal description of Apertium RDF you can read this blog entry . For more technical details, we refer to this paper.]
How translations are represented in the input data source
Each Apertium bilingual dictionary was converted into three different objects in RDF:
- Source lexicon
- Target lexicon
- Translation Set
As a result, two independent monolingual lexicons were published on the Web of Data per dictionary, along with a set of translations that connects them. Notice that the naming rule used to build the identifiers (URIs) of the lexical entries allows to reuse the same URI per lexical entry across all the dictionaries, thus explicitly connecting them. For instance the same URI is used for the English word “bench” as a noun: http://linguistic.linkeddata.es/id/apertium/lexiconEN/bench-n-en along the whole Apertium RDF graph, no matter if it comes from, e.g., the EN-ES dictionary or the CA-EN.
The following picture illustrates a translation example in Apertium RDF of "bench"@en →"banco"@es in the EN-ES translation set ('lemon' prefix refers to http://www.lemon-model.net/lemon# and 'tr' prefix to http://purl.org/net/translation#):
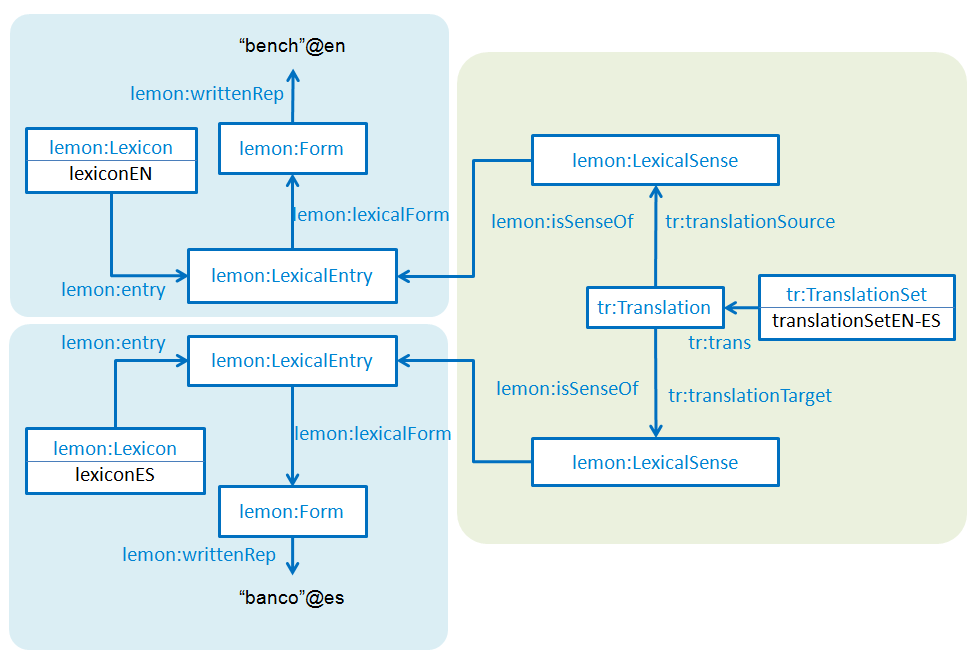
You can find the RDF code of the above example in the following
links: Source
lexicon (EN), Target
lexicon (ES) and Translation
Set (EN-ES)
[Further reading: the above details were taken from the W3C community report on Guidelines for Linguistic Linked Data Generation: Bilingual Dictionaries ]
How to get the source data
There are several options to obtain the data of the Apertium RDF graph:
- Querying the data online through the SPARQL endpoint. An example of a query to get direct translations from a single term can be found here. An example of a query to get the whole list of translations from the EN-ES translation set can be found here.
- Downloading the data dumps available in Datahub.To that end, follow the link here to obtain the list of the 22 bilingual dictionaries. You can visit those of your interest and download the data by clicking on "Zipped RDF Data Dump". Once you have stored the RDF data locally, you can process and query it by means of RDF frameworks like Apache Jena or Apache Fuseki, for instance.
- SHORTCUT: If you are not a Semantic Web geek, you can
get the data dumps in TSV (Tab Separated Value) format from this
link. The
zipped dump contains 22 tsv files, one per translation set,
containing the following information per row (tab separated):
"source written representation"
"source lexical entry (URI)"
"source sense (URI)"
"translation (URI)"
"target sense (URI)"
"target lexical entry (URI)"
"target written representation"
"part of speech (URI)"
Possibly, not every participating system will need all the above information, but we keep it for completeness. - MONOLINGUAL LEXICONS

In addition to the TSV files with the translation pairs, we add here, for convenience, a link to the monolingual lexicons of the evaluated languages (EN, FR, PT), as they appear in Apertium RDF, containing the following information (tab separated):
"lexical entry (URI)"
"written representation"
"part of speech (URI)"
How to build a results data file
Once you have run your system on the source data (initial
translations) and get the output data (inferred translations), you
have to load the results into a file per language pair in TSV (tab
separated value) format. The name of the file has to follow the
pattern:
[system's name]_trans_[source language]-[target
language].tsv
For instance: TIADbaseline_trans_en-fr.tsv.
The data file has to contain the following information per row
(tab separated):
"source written representation"
"target written representation"
"part of speech"
"confidence score"
The confidence score takes float values between 0 and 1 and is a measure of the confidence that the translation holds between the source and target written representations. If a system does not compute confidence scores, this value has to be put to 1.
Evaluation process
Once you have sent the output data (inferred translations), the evaluation of the results will be carried out by the organisers against the test data, consisting of manually compiled pairs of K Dictionaries. The performance will be measured in terms of precision, recall, F-measure and coverage, and the results published in this website.
Validation data
Although the golden standard will remain not directly accesible to the public to allow a blind evaluation, K Dictionaries has made available a portion of it to the TIAD participants, in particular a 5% of randomly selected translations for each language pair, upon request by email to the organisers. The goal of these data is to allow participants to analyse the nature of the data that will be used as gold standard for the evaluation, as well as to give them suitable data for running some validation tests and, maybe, to analyse negative results. The validation data will not be used for the final evaluation.